March 21, 2023 Azure Cosmos GraphDatabase Presentation
Graph Database in Azure Cosmos
I’m fortunate to be a part of a talented team that will be building a new product. We’ve compared using a graph database with a relational database. We’ve decided to use a graph database. We’ve been learning about graph databases and using GremlinDB inside of Azure Cosmos. It was important to prototype what the graph might look (we used draw.io) like before starting.
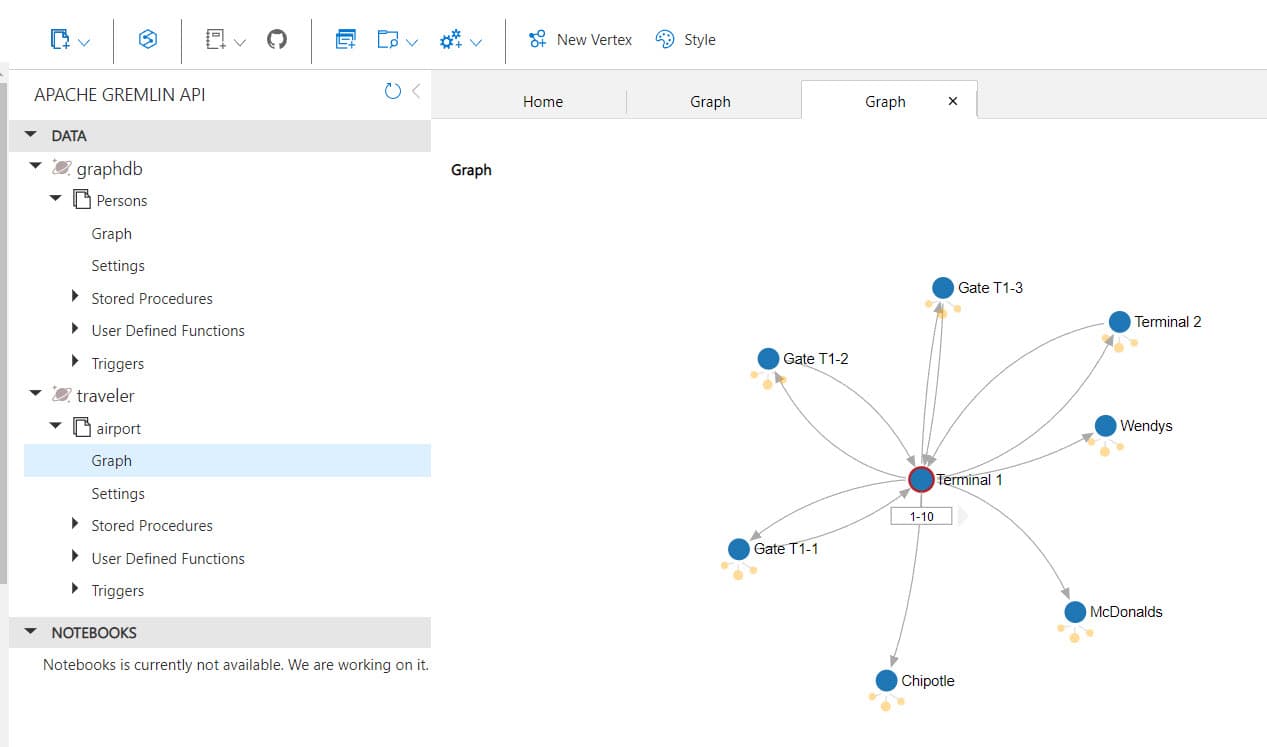
Here’s what the graph looks like in the Azure Portal (using Learning Azure Cosmos DB | Pluralsight as a guide)
What is a Graph Database?
A graph database is a type of database that uses graph theory to store, manage, and query data. In a graph database, data is represented as nodes (also known as vertices) and edges. Nodes represent entities, while edges represent the relationships between them.
Each node and edge in a graph database can store properties, which are key-value pairs that provide additional information about the node or edge. These properties can be used to filter and query the data in the graph.
Graph databases are particularly useful for managing data that has complex relationships, such as social networks, recommendation engines, and fraud detection systems. They are also well-suited for applications that require real-time analysis of large datasets.
(thanks ChatGPT for the answer)
when should I use a graphDb? answer by Phind.com
“the main thing I love about it is, the ability to be extremely flexible in the modeling of relationships” ~ Kyle after experience
Prototyping Questions
- What will the relationships be? Does a graph make sense?
- What are the edges and vertices?
- What data do we need to store?
- Would a relational database be better?
Terminology
I started with this excelent course Learning Azure Cosmos DB | Pluralsight .
- Graph Container
- Vertex (entity) and edge (1 way relationship)
- CRUD - GraphSON (convention to define vertices and edges and persist) and Gremlin (functional step by step language create and query), based on Apache TinkerPop
- NoSQL storage - the data is stored in JSON
Relationships
Complex, many to many, excessive joins, analyze interconnected data/relationships social, recommendations, knowledge graphs, conference
Vertex
- Id (within partition key) - like others
- label (type) Edge
- cardinality
- 2 vertices being connected.
- ways to represent the relationships
- examples: know, interested, runsOs, users, located
- use domain language to match with business terminology
Gremlin Querying
g.addV('person').property('id', 'John')
g.addE('worksAt')
.property('weekends', true)
.to(g.V().has('id', 'Acme'))
a query from https://learn.microsoft.com/en-us/azure/cosmos-db/gremlin/introduction
g.V().
hasLabel('person').
order().
by('firstName', decr)
Gremlin Steps for Querying
- Map
- Filter
- Side-effect
- walking on the graph, collecting information
- .store()… .cap()
- makes a union/unique
- Barrier
- Branch
filter out as soon as you can will be faster and cheaper.action-area
“you have in there the 1 way relationship but that is kinda true, for instance an vertext in partition A will store all of its outward edges in partition A but incoming ones could be stored in a different partition. This can cause issues when you are doing a lot of different relationship queries. It’s a pretty complex but subtle thing that will kill you at scale.” ~Kyle from recent experience coding an api
Pay attention to your RU usage (in Azure Cosmos) / performance
to demo the subtle differences in the partitioned scenario, this query would be excellent in the partitioned graph.
string query = g.V("thomas").OutE("knows").Where(__.InV().Has("id", "mary")).Drop().ToGremlinQuery();
but this would could absolutely kill your RU’s
string query = g.V("thomas").InE("knows").Where(__.InV().Has("name", "mary")).Drop().ToGremlinQuery();
Demo code from Pluralsight
When I’m presenting, I’ll share a few snippets from Learning Azure Cosmos DB | Pluralsight .
Azure Cosmos DB
"Azure Cosmos DB for Apache Gremlin is a graph database service that can be used to store massive graphs with billions of vertices and edges. You can query the graphs with millisecond latency and evolve the graph structure easily. The API for Gremlin is built based on Apache TinkerPop, a graph computing framework that uses the Gremlin query language."
from Azure Cosmos has a Gremlin implementation . The data is provisioned, etc. just the same as Table or Document or others in Cosmos DB. There is a long list of benefits. We see Azure Cosmos as a great fit for our app. There is a cost, but we think it will fit our product well.
You need to choose the Partition Key when you create the graph. This is using a partitioned graph, which just means that vertexes are stored in different partitions so you have to be careful about your modeling.
serverless or provisioned? Serverlesss is more restricted “Unavailable (serverless accounts can only run in a single Azure region)”, billed per hour for number or Rus
Some differences when using Azure Cosmos DB
Azure Cosmos DB Graph engine runs breadth-first traversal while TinkerPop Gremlin is depth-first. This behavior achieves better performance in horizontally scalable system like Azure Cosmos DB.
Watch out for compatibility issues with the Gremlin .Net Nuget package by Apache TinkerPop -
Azure Cosmos DB for Gremlin support and compatibility with TinkerPop features | Microsoft Learn
3.4.13 was released on Jan 13, 2022 :-(. Also the constructor new GremlinClient(gremlinServer, mimeType: GremlinClient.GraphSON2MimeType) to avoid error: "Gremlin Malformed Request: GraphSON v3 IO is not supported."
LINQ Possibilities
You may want to avoid using strings in the queries. If you’re up for an abstraction and another dependency, check out GitHub - ExRam/ExRam.Gremlinq: A .NET object-graph-mapper for Apache TinkerPop™ Gremlin enabled databases. was the one that was the most up to date that I found on Github.
Here’s an example from their page:
var g = AnonymousTraversalSource.Traversal();
string query = g.V("thomas").OutE("knows").Where(__.InV().Has("id", "mary")).Drop().ToGremlinQuery();
// query will be "g.V('thomas').outE('knows').where(inV().has('id', 'mary')).drop()"
// with strong typing
string query = g.V<Person>("thomas").OutE<Knows>().Where(__ => __.InV<Person>("mary")).Drop().ToGremlinQuery();
After using Gremlinq in our project, Kyle says “Gremlinq is awesome” :-).
GitHub - csharpsi/Gremlin.Net.Extensions looks to be another option.
I recommend doing some prototyping/experimenting to see what works best for you.
Authentication
In Azure you have to use the primary key/password, in the [].Net Conf 2022 video]( https://youtu.be/sQb4pyEuEcM ) at minute 16 she says “that doesn’t work for the database level”. That may change in the future, check the docs
Connect to GraphQL
More Videos
-
Navigating Graphs in Azure Cosmos DB using Gremlin.Net | .NET Conf 2022 - YouTube
- #DotNetConf
- Use Gremlin.Net.Extensions
- primitive types for properties only
- https://github.com/sadukie/dotnet-conf-2022-gremlin-net-demo
- PRACTICAL GREMLIN: An Apache TinkerPop Tutorial (kelvinlawrence.net)
- Ingest data in bulk in Azure Cosmos DB for Gremlin by using a bulk executor library | Microsoft Learn
- Using Gremlin.NET and Azure Cosmos DB for code analysis - Events | Microsoft Learn
- Azure Cosmos DB – Graph API Pattern and Practices - YouTube Jan 2, 2019
- How to use the Gremlin API with Azure Cosmos DB | Azure Friday - YouTube 2019
- GraphQL over Azure Cosmos DB - where to start? Cosmos DB Conf 2021
-
Graph of Thrones, Azure Cosmos DB vs. The Seven Kingdoms | Alan Smith | Azure Cosmos DB Conf 2022 - YouTube
- SQL compared to Gremlin: https://youtube.com/watch?v=CZsFec72CpY&feature=shares&t=544
- Using Gremlin API and Apache Airflow to facilitate Complex System Integrations - Cosmos DB Conf 2022
- Using Gremlin.NET and Azure Cosmos DB for code analysis - Cosmos DB Conf 2022
Cheatsheets from .Net Conf 2022
- Azure Cosmos DB PDF query cheat sheets | Microsoft Learn
- Gremlin Cheat Sheet 101 (dkuppitz.github.io)
More Links
note: Kyle is a great innovative team member, software engineer, architect and leader. He said I could quote him in this article.
A Power Point Presentation for lunch and learn
My Omnitech Lunch and Learn Power Point
Check out my Resources Page for referrals that would help me.
Use Swan Bitcoin to onramp with low fees and automatic daily cost averaging and get $10 in BTC when you sign up.
